Generative künstliche Intelligenz („Generative AI“) ist ein vielseitiges Tool für die Verarbeitung, Analyse, Erstellung und innovative Nutzung von Daten. Sie ermöglicht Effizienzsteigerungen im Umgang mit großen Datenmengen und fördert die Interaktion als benutzerfreundliche Schnittstelle zum Menschen. Seit der Veröffentlichung von ChatGPT finden Generative AI und Large Language Models (LLMs) durch vielfältige Anwendungsmöglichkeiten den Weg aus der IT-Welt des Silicon Valley in die Industrie.
Im Rahmen des 3. Events der aktuellen „DIVE = Digitale Industrie Verständlich Erklärt“-Veranstaltungsreihe wurde das Thema Generative AI für den Einsatz in Unternehmen näher beleuchtet: In Anschluss an die Begrüßung durch Mag. Anita Wautischer (Geschäftsführerin der Sparte Industrie der Wirtschaftskammer Salzburg) folgte eine Kurzvorstellung der Initiative „Digitale Industrie Verständlich Erklärt“ der Plattform Industrie 4.0 durch DI Roland Sommer.
GENERATIVE KI UND FOUNDATION MODELS
Professor Dr. Michael Gadermayr (FH Salzburg) führte in das Thema „Generative AI“ ein, indem er zunächst die grundlegenden Begriffe und unterschiedlichen Teilbereiche der „künstlichen Intelligenz“ strukturiert erklärte und dabei die zentrale Frage „Was ist künstliche Intelligenz?“ beantwortete. – Kurz gesagt: „KI zielt darauf ab, Systeme zu schaffen, die in der Lage sind, Aufgaben zu bewältigen, die menschliche Intelligenz erfordern.”
Künstliche Intelligenz lässt sich in verschiedenen Ebenen bzw. Unterkategorien einteilen:
- Ein zentraler Teilbereich ist das maschinelle Lernen (Machine Learning), das Unterkategorien wie „shallow learning“ und „deep learning“ beinhaltet.
- Generative KI, wie beispielsweise das Programm ChatGPT, stellt wiederum eine spezifische Art der Anwendung von „deep learning“-Algorithmen dar, die Inhalte wie etwa Texte, Bilder oder Videos eigenständig erstellen können.
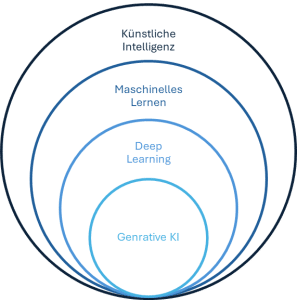
Um ein grundlegendes Verständnis und einen Überblick im „Buzz Word“ Dschungel zu erhalten, ging er einen Schritt zurück und beleuchtete maschinelles Lernen näher: Klassisches maschinelles Lernen zielt auf Mustererkennung in großen Datensätzen ab und wird unterteilt in überwachtes (supervised) und unüberwachtes (unsupervised) Lernen.
- Beim überwachten Lernen werden Trainingsdaten und Labels benötigt, die von einem „Supervisor“ vorgegeben werden. Es wird etwa durch den Menschen festgelegt, ob ein Objekt im Trainingsdatensatz ein Auto ist oder nicht.
- Im Fall des unüberwachten Lernens ist hingegen kein „Supervisor“ notwendig: Es werden keine Labels von außen vorgegeben. Es werden Cluster (Häufigkeiten) von Datenpunkten gebildet, die idealerweise Kategorien entsprechen.
Als Beispiel für Deep-Learning Anwendungen nannte Prof. Gadermayr die Bildanalyse zur Bestimmung von Hautkrebs sowie die Gesichtserkennung mittels sog. „Deep-Convolutional Networks” oder „Transformer“ Architekturen.
Das sogenannte „Transformer Modell“ bildet die Grundlage für vielseitig einsetzbare Sprach- und Bildverarbeitungssysteme (und weitere). Dabei handelt es sich um ein „Foundation Model“ – also um ein Basismodell, welches riesige Datensätze benötigt, um trainiert zu werden und anschließend auf unterschiedliche Aufgaben angewendet werden oder durch weitere Trainings für spezifische Anwendungen fein-abgestimmt werden kann. ChatGPT ist ein Beispiel, aber auch anderer Programme u.a. zur Text- und Bild Verarbeitung fallen in diese Kategorie. „Foundation Models“ entwickeln sich in Richtung „generischer Modelle“, da sie weniger problembezogenes Training erfordern bzw. oft mit relativ kleinen zusätzlichen Datensätzen performant sind, und so insgesamt eine breite Palette an Anwendungen ermöglichen.
Stärken von Deep Learning:
- Oft präzise und meistens effizient
- Hochgradig übertragbar auf Anwendungsgebiete (Inferenz)
- Sparen menschliche Zeit
- Ermöglichen schnelle Datenanalyse
- Unterstützen quantitative Messungen
Schwächen von Deep Learning:
- Schneiden oft schlecht ab, wenn die Trainingsdaten klein/unausgewogen/variabel sind, d.h. sie sind anfällig für Verzerrungen (Biases)
- „verstehen“ die Welt nicht bzw. kein „vernetztes Denken”
- „Halluzinationen
NO MAGIC: DIE ZUKUNFT DER KI
Dr. Bernhard Nessler (Software Competence Center Hagenberg – SCCH) knüpfte an die Einführung an und räumt mit Mythen im Bereich der künstlichen Intelligenz (KI) auf. Er verdeutlichte die grundlegenden Unterschiede zwischen menschlicher und maschineller Intelligenz: Obwohl wir oft ähnliche Begriffe wie „verstehen“, „denken“, „lernen“ und „wissen“ verwenden, unterscheiden sich die zugrundeliegenden Mechanismen der biologischen und maschinellen Datenverarbeitung grundsätzlich. Treffender beschreiben ließe sich KI durch Begriffe wie „komplexe Datenverarbeitung“, „Optimierung“, „Statistik“, „Berechnung“, „Vorhersage“ und „Klassifikation“. Diese Begriffe sind weniger beladen mit menschlichen Vorstellungen, vermeiden daher Missverständnisse, und helfen dabei, die Technologie „KI“ tendenziell sachlicher zu betrachten und mit Aspekten wie „Daten“, „Zielen“ und „mathematischen Berechnungen“ zu verknüpfen.
Maschinelle Intelligenz ist nämlich Datenverarbeitung basierend auf mathematischen Berechnungen und Optimierung. Menschliche Intelligenz umschließt u.a. auch Intuition und Bauchgefühl (System 1) und rationales Denken (System 2) und die Kombination davon. In beiden Systemen gibt es dennoch in einigen Aspekten Ähnlichkeiten mit künstlicher Intelligenz.
Während die Parallelen zu „System 2 – rationales Denken“ einleuchtend erscheinen, mag es überraschend wirken, das maschinelles Lernen (ML), Deep Learning und Large Langue Models (LLMs), wie ChatGPT, sich mit „System 1“ vergleichen lassen. D.h. es werden Entscheidungen zu ML, DL und bei LLMs oft analog zum System 1 getroffen. Das liegt daran, dass sich sog. Entscheidungen „aus dem Bauch heraus“ – ähnlich wie maschinelles Lernen – abstrahieren lassen können als: Ableitungen für die Zukunft basierend auf der Verarbeitung von mehr als 10.000 Inputs sowie auf Erfahrungen. Entscheidungen, die auf maschinellem Lernen beruhen, erscheinen intuitiv, da sie oft nicht logisch hergeleitet oder vollständig erklärbar sind (die zugrundeliegende Logik der Konklusion ist nicht ersichtlich bzw. es handelt sich um Ergebnisse, die keine „justifiable conclusion“ darstellen). Sie basieren auf „Erfahrungswerten“ abgeleitet aus den eingespielten Trainingsdaten und ermöglichen durch komplexe und teils schwer durchschaubare Berechnungsmethoden Vorhersagen für zukünftige Szenarien. Ergo: Ein ML-Modell erkennt Muster in den Daten und nutzt diese, um Klassifikationen festzulegen oder Vorhersagen zu treffen, ohne dass es einen expliziten, logischen Beweis (für den Zusammenhang) liefern kann.
Wie wird ein Large Language Modell (LLM) trainiert?
Ein LLM bzw. großes Sprachmodell (wie z.B. ChatGPT) wird durch enorme „Pre-Trainingsdatensätzen“, beispielsweise Texte aus dem Internet, trainiert. Diese allgemeinen Daten werden in einem Fine -Tuning durch Aufgaben-spezifische Daten ergänzt. Zu bedenken sind in Bezug auf das Training mögliche Verzerrungen in den Daten, welche zu voreingenommenen Ergebnissen führen (Biases) sowie urheberrechtliche Problematiken (Copyright-Bruch). „Maschinelle Intuition“ bzw. auch der Output eines LLM-Modells entsteht durch das Berechnen von Ähnlichkeiten ergänzt durch das Hinzufügen von Hintergrundinformation (z.B. in Bezug auf welche Merkmale der Daten relevant für eine spezifische Aufgabe sind).
GENERATIVE KI – GRUNDLAGEN, FALLSTRICKE, CHANCEN
Dr. Stefan Gindl (Research Studios Austria Forschungsgesellschaft – RSA FG) setzte mit einem Fokus auf die Anwendung von Large Language Models bzw. Sprachmodellen fort.
Er gibt eine Übersicht (nicht abschließend) über die unterschiedlichen Einsatzbereiche von LLM-Modellen und aktuell verfügbarer Programme:
- Text-generierende KI: ChatGPT, Google Gemini, Claude, etc.
- Bild-generierende KI: Dall-E, Midjourney, Stable-Diffusion, etc.
- Video-generierende KI: Sora (OpenAI), HeyGen, Synthesia, etc.
- Konversations-generierende KI: Notebook LM
Seit 2018 haben sich unterschiedlichen LLM-Software-Angebote rasant erweitert und verbessert. Neben kommerzieller Software gibt es auch einige „Open Source Modelle“.
Kommerzielle LLms vs. Open Source (Stand Oktober 2024):
- Kommerzielle LLMs zumeist bedeutend leistungsfähiger
- Bezahlung mit Abo-Modellen
- Kostenpflichtiger API-Zugriff
- Open Source:
- Open-Source-Modelle zunehmend leistungsfähiger
- Beispiel:
- Mistral (https://mistral.ai/news/mistral-large/)
- Llama (https://llama.meta.com/)
In beiden Fällen sind große Rechenkapazitäten notwendig.
Welche Chancen bieten Large Language Modelle?
- Helfen beim Umgang mit großer Wissensbasen und deren Interpretation für Anwender:innen
- Inspirieren bei der Ideenbildung
- Unterstützen bei Content-Creation
- Zugang zu individuellem Graphik-Design, ohne die dafür notwendigen Fähigkeiten
- Unterstützung beim Proof-Reading.
Anhand eines Beispiels aus der Prozessautomatisierung in der Aquaponik (Fischzucht in einem Kreislaufsystem) lassen sich einige Chancen illustrieren: Ein „virtueller Consultant“ kann unter Einbeziehung von Umgebungsvariablen der Anlage (Sensordaten) über Eingriffe das System beraten (z.B. ob Fische mehr Futter brauchen). Das KI-Programm kann basierend auf Messdaten potenzielle Gründe für die Werte erklären und geeignete Maßnahmen beschreiben und empfehlen Ähnlich könnte dieses Prinzip sich auf ein System/einen Prozess in der Produktion anwenden lassen.
Auch können LLMs beispielsweise im Bildungsbereich hilfreich sein: Das Tool Teachino ist auf die Unterstützung von Lehrkräften bei der Unterrichtsgestaltung spezialisiert. Zu den Funktionen zählt beispielsweise Inspiration mittels Inhaltsvorschlägen, übersichtliche Planung und Tracking, strukturierte Ablage von Inhalten und flexible Aufbereitung, Möglichkeit zur Zusammenarbeit mit anderen Lehrenden und selektiver Zugriff für Schüler:innen.
Eine weitere Anwendung, welche von Unternehmen genutzt werden kann, ist die automatisierte Aufbereitung und Generierung von Informationsmaterial (z.B. mit NotebookLM) oder in Form eines KI generierten Video-Chatbot, der unterschiedliche Sprachen spricht und als Avatar mit Kunden interagieren kann (z.B. mit HeyGen).
Welche Fallstricke sollten beachtet werden?
- Das Blackbox Problem: Entscheidungen entstehen auf Grundlage intransparenter und komplexer Modelle, deren Entscheidungsprozesse für den Menschen nicht nachvollziehbar sind. Das erschwert die Logik hinter Entscheidungen zu verstehen oder Fehlerquellen zu identifizieren (wie zum Beispiel voreingenommene Trainingsdaten und daraus resultierende Biases). Im Gegensatz dazu steht „explainable“ (oder White-Box) KI, die inhärent interpretierbar ist. Diese kann jedoch oft nicht im selben Umfang komplexe Muster erfassen wie beispielsweise künstliche neuronale Netze, die zur Familie der Black-Box-KI gehören.
- Energieverbrauch: KI-Programme benötigen viel Energie in der Ausführung, wobei Text basierte Aufgaben (Anhaltspunkt: 0,0068 kWh pro 1.000 Interferenzen) energieeffizienter ausgeführt werden können als Bild-Basierte Aufgaben (ca.1,35 kWh/Bildgenerierung). Zum Vergleich: Letzteres braucht bis zu 50% einer Smartphone Ladung für die Generierung eines Bildes.[2]
- Behinderung von Lerneffekten: Studien zeigen, dass die Unterstützung von KI z.B. beim Programmieren, Vor- und Nachteile in Bezug auf die Lerneffekte der Anwender:innen haben kann.
- Auswirkungen auf die menschliche Kreativität: Eine Studie hat gezeigt, dass generative KI die individuelle Kreativität von Schriftstellern steigern kann, aber das Risiko beinhaltet den kollektiven Neuheitsgehalt von Kreationen zu mindern.
Weitere zu beachtende Fallstricke:
- Over-promising und Hype
- Bei unklarem Verwendungszweck gibt es keine positiven Effekte
- Überflutung mit digitalem Content
- Abflachen der Kreativität, Eintönigkeit in der Content-Erstellung
- Fehlende Notwendigkeit, einen geschliffenen Sprachstil zu erwerben
- Unreflektiertes Übernehmen von Inhalten, kein Hinterfragen des Wahrheitsgehalts (Halluzinationen)
ANWENDUNG VON GENERATVER KI – REALITY INSIGHTS
Thomas Lamprecht (Tietoevry) baute auf den Beiträgen der Vorredner auf und zeigte wie LLMs in der Praxis angewendet werden können.
Für seine Präsentation nutzte er bereits die Unterstützung von ChatGPT. Der folgende Einleitungstext für seinen Vortrag wurde von ChatGPT vorgeschlagen: „In den nächsten Minuten möchte ich mit Ihnen teilen, wie generative AI nicht nur die Art und Weise, wie wir produzieren, verändert, sondern auch, wie sie uns ermöglicht, völlig neue Produkte und Dienstleistungen zu entwickeln. Wir werden gemeinsam erkunden, wie diese Technologien implementiert werden können (…).“ Es gilt richtig zu „prompten“ und den Text anschließend individuell an die Bedürfnisse anzupassen.
Auch zur Erstellung der Power Point Präsentation kann generative KI genutzt werden: Man entwirft eine kurze Beschreibung des erwünschten Ergebnisses, wie zum Beispiel: „Erstelle eine Präsentation für eine Keynote vor Vertretern erfolgreicher Unternehmen. Sie soll inspirieren und die Möglichkeiten von KI aufzeigen. Ich möchte Beispiele und Einblicke für den praktischen Einsatz von KI haben. Besonders die Vorteile sind interessant.“ Außerdem kann ein bereits vorhandener Präsentations-Entwurf hochgeladen werden.
Es handelt sich um sehr generische Beispiele in Bezug auf PowerPoint und Redetext. Diese Anwendungen sind daher nicht Industrie spezifisch.
Diese Demonstration zeigt also die Vielseitigkeit generativer KI-Tools, die viele Bereiche der Büroarbeit effizient unterstützen können. Allerdings lässt sich nach anfänglicher Euphorie oft Ernüchterung beobachten, wenn es um den erhofften Mehrwert und die transformative Wirkung der Technologie durch den Einsatz im Unternehmen geht. Auch hier gilt es, ähnlich wie bei anderen neuen Technologien, dennoch nicht die Wirkung und langfristige Transformation zu unterschätzen, die sich manchmal erst schrittweise entwickelt.
„Mindful AI“ – Strategien für nachhaltige Anwendungsfälle:
Unternehmen sollten gezielt nachhaltige Use Cases entwickeln und dabei strategisch vorgehen:
- Ziele definieren und Geschäftsprozesse analysieren – Die Herausforderungen und Potenziale der KI in spezifischen Prozessen erkennen.
- Erfolgsmetriken festlegen – Kriterien für die Bewertung des KI-Einsatzes formulieren.
- Passende Use Cases auswählen und implementieren – Praktische Anwendungen wie maßgeschneiderte, KI-gestützte Assistenten umsetzen.
Eine einfach umsetzbare Anwendung generativer KI ist die Entwicklung eines individuell angepassten Chatbots, der auf spezifische Aufgaben zugeschnitten ist. Thomas Lamprecht zeigt live vor, wie beispielsweise ein „Industrie 4.0 Assistent“ erstellt werden kann: Es wird dem System (Open AI) mitgeteilt, dass es auf Daten der Plattform Industrie 4.0, wie Websites, Publikationen und Präsentationen zugreifen soll. Der entsprechende „Prompt“ könnte lauten:
- „Du bist ein Mitarbeiter für die Plattform Industrie 4.0 in Österreich. Du kümmerst dich um Events, Publikationen und beantwortest Fragen von Mitgliedern.“
- „Nutze dafür immer plattformindustrie40.at und gib bei Eventanfragen Name, Kurzbeschreibung, Ort, Datum und Uhrzeit an.“
Effiziente KI-Anwendungen bei Tietoevry:
Tietoevry setzt GPT-Modelle gezielt für integrierte Assistenzsysteme und Lösungen ein, darunter:
- Ask HR – Ein Chatbot für personalbezogene Anfragen.
- Legal Document Expert – Unterstützung bei juristischen Dokumenten.
- Project Expert – Hilfe bei Projektmanagement-Aufgaben.
- Works Council Chatbot – Kommunikation mit Betriebsräten.
- Universal Chat & Document Support – Allgemeine Unterstützung bei Dokumenten- und Kommunikationsprozessen.
Diese Anwendungsbeispiele unterstreichen das Potenzial von generativer KI, Unternehmen effizienter und innovativer zu gestalten.
WEITERE USE CASES FÜR KI ALLGEMEIN – Inspiration
Roland Sommer präsentierte einige Anwendungsbeispiele für KI in der Industrie aus dem Erfahrungsschatz der Plattform.
ANGEBOTE UND FÖRDERUNGEN IN SALZBURG:
Roland Sommer (Plattform Industrie 4.0) bot einen Überblick über aktuelle, praxisrelevante Förderprogramme und Angebote im Bereich Industrie 4.0, Digitalisierung und Kreislaufwirtschaft. Neben Förderprogrammen der FFG, aws sowie der Wirtschaftskammer und Bundesländer-spezifischen Angeboten, sind über ganz Österreich verteilte (European) Digital Innovation Hubs, COMET-Zentren und Pilotfabriken wichtige Anlaufstellen. Details finden Sie auf der DIVE-Website
Im Rahmen des European Digital Innovation Hubs „AI5production“ und der Mittelstandsinitiative DIVE „Digitale Industrie Verständlich Erklärt“ werden regelmäßig in ganz Österreich regionale Veranstaltungen zu ausgewählten Digitalisierungsthemen angeboten, bei denen Austausch und Diskussion mit Expert:innen aus Wissenschaft und Industrie im Vordergrund stehen. Neben technologie-spezifischen Einblicken, wird ein Überblick über Förderungen, Trainings, praxisorientierte Angebote u.Ä. in Österreich vermittelt. Der Auftakt der zweiten DIVE-Eventreihe fand in Niederösterreich an der FH St. Pölten statt und beleuchtete den digitalen Produktpass. Die zweite Veranstaltung zum Thema Datenaustausch folgte in Oberösterreich im „FutureDome“ der Firma FILL in Gurten. Das 3. Event zum Thema generative KI fand in Salzburg in den Räumlichkeiten der Wirtschaftskammer-Bezirksstelle Pinzgau in Zell am See statt. Es wurde in Kooperation mit der Wirtschaftskammer Salzburg (Sparte Industrie), der WK Bezirksstelle Pinzgau und der Industriellenvereinigung Salzburg organisiert und durch den österreichischen European Digital Innovation Hub AI5-Production unterstützt.
PRÄSENTATIONEN ZUM DOWNLOAD:
- Stefan Gindl: Generative AI – Grundlagen, Fallstricke, Chancen (Okt 2024)
- Thomas Lamprecht: Generative AI – Reality Insights (Okt 2024)
NÜTZLICHE INFORMATIONEN ZUM KÜNSTLICHER INTELLIGENZ:
- Publikation zu vertrauenswürdiger KI: AI4Good – Ein Praxisleitfaden zur erfolgreichen Einführung von KI-Systemen
- AI-Act: Das KI-Gesetz gibt Entwicklern und Betreibern von KI klare Anforderungen und Verpflichtungen in Bezug auf spezifische Anwendungen von KI vor.
Zum Mitmachen:
- AI Pact: Die Initiative der europäischen Kommission unterstützt Organisationen bei der Vorbereitung auf die Umsetzung des AI Act. U.a. werden Informations-Events angeboten.
- European Digital Innovation Hub – AI5Production: Der österreichische Hub unterstützt produzierende KMU und Mid-Caps bei der digitalen Transformation und damit auch bei der Einführung von KI-Anwendungen. Im Rahmen des „Test Before Invest“ Services können konkrete Use-Cases gemeinsam mit Expert:innen erprobt werden. Bis zu 40.000 Euro werden zu 100% gefördert. Außerdem wird kostenloser Zugang zu Trainings, Unterstützung bei der Finanzierungssuche und Vermittlung zu Partnern aus dem europäischen Netzwerk geboten. Nehmen Sie unverbindlich Kontakt auf.
Weitere nützliche Links finden Sie in den Präsentationen.
Ansprechpersonen:
Plattform Industrie 4.0:
- Roland Sommer, sommer@plattformindustrie40.at
- Michael Fälbl, faelbl@plattformindustrie40.at
- Stefanie Werderits, werderits@plattformindustrie40.at
WK Salzburg (Sparte Industrie):
- Anita Wautischer: awautischer@wks.at
WK Bezirksstelle Pinzgau:
- Dietmar Hufnagl: dhufnagl@wks.at
FH Salzburg:
- Dr. Michael Gadermayr, michael.gadermayr@fh-salzburg.ac.at
Software Competence Center Hagenberg – SCCH:
- Bernhard Nessler, bernhard.nessler@scch.at
Research Studios Austria Forschungsgesellschaft – RSA FG
- Stefan Gindl, stefan.gindl@researchstudio.at
Tietoevry:
- Thomas Lamprecht, lamprecht@tietoevry.com
European Digital Innovation Hub – AI5Production:
- Ing. Franz Sümecz, franz.suemecz@tuwien.ac.at
- Claudia Schickling, pilotfabrik@tuwien.ac.at
- Ing. Christian Wögerer, christian.woegerer@profactor.at
